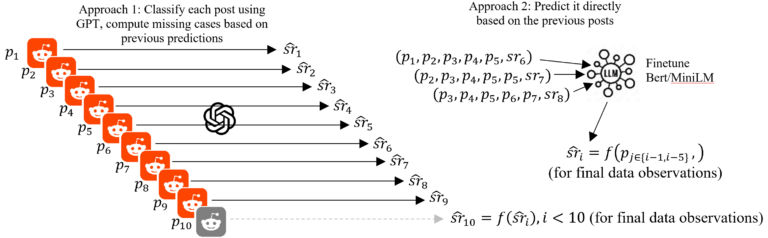
Understanding Language Beyond Words: Building IdiomX for Multilingual AI and Idiom Interpretation
In his Deep Learning project, DSTI MSc student Ayman Sharara developed IdiomX, a multilingual AI dataset and benchmark designed to help machines understand idioms, figurative expressions, and hidden meaning across English, Arabic and French. By combining data engineering, NLP, LLM-based enrichment and validation, IdiomX moves AI beyond literal translation towards